









![[Gamma] Scalping Please](https://ibkrcampus.com/wp-content/smush-webp/2024/04/tir-featured-8-700x394.jpg.webp "[Gamma] Scalping Please")




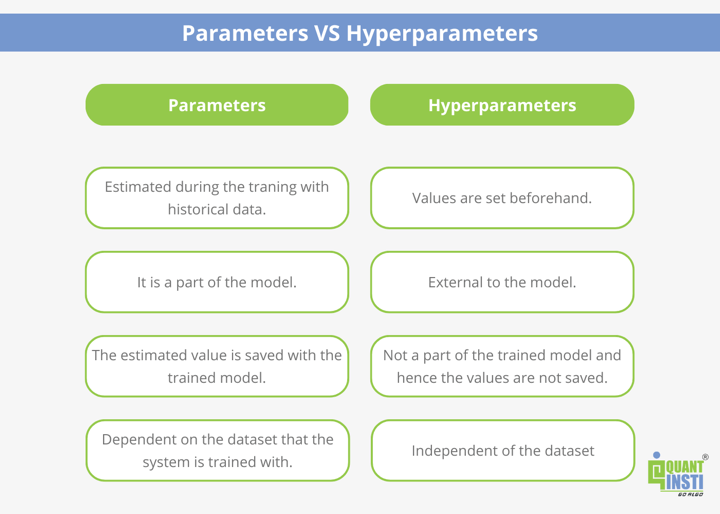
Hyperparameters are nothing but those values that the model uses to learn the optimal parameters in order to correctly map the input features (independent variables) to the labels or targets (dependent variable).
For example, the parameter is the weights in an artificial neural network (ANN). The hyperparameters are the specific parameters that optimise and control the training process.
Confused, right? Not to worry.
We will discuss everything from what the parameters and hyperparameters are to how the hyperparameters can be used to improve your strategy’s performance!
Hence, hyperparameters are a group of parameters that help train a machine learning model to provide the required results every time.
In this blog, we will discuss all about parameters, hyperparameters and hyperparameter tuning. This blog covers:
- What are the parameters?
- What is hyperparameter and hyperparameter tuning?
- Examples of hyperparameters
- Importance of hyperparameters
- Hyperparameters vs parameters
- Categorisation of hyperparameters for training machine learning model
- Hyperparameters for optimisation
- Hyperparameters for specific models
- How to tune hyperparameters?
What are the parameters?
Parameters are learned by the model purely from the training data during the training process. The machine learning algorithm used tries to learn the mapping between the input features and the targets or the desired output(s).
Model training typically starts with parameters being set to random values or set to zeros. As training/learning progresses the initial values are updated using an optimization algorithm. An example of an optimization algorithm is gradient descent.
At the end of the learning process, model parameters lead to the model’s training.
Examples of parameters
Some examples of parameters in machine learning are as follows:
- The weights of linear and logistic regression models.
- The cluster centroids in clustering
What is hyperparameter and hyperparameter tuning?
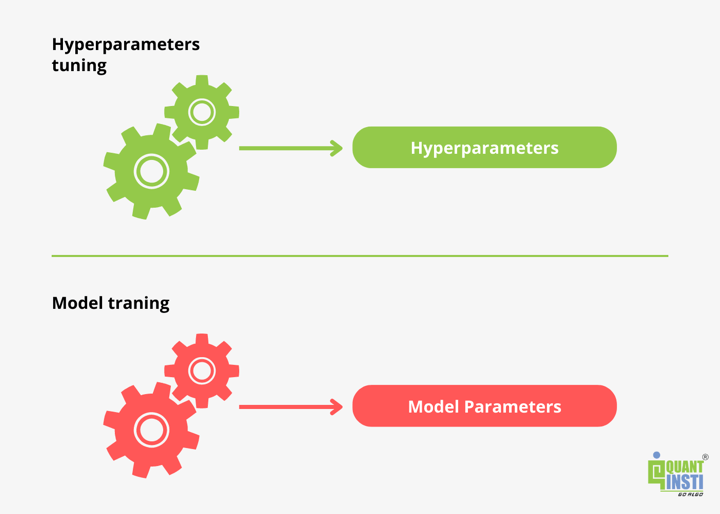
A hyperparameter is a parameter set before the learning process begins for a machine learning model. Hence, the algorithm uses hyperparameters to learn the parameters.
These parameters can be tuned according to the requirements of the user and thus, they directly affect how well the model trains.
When creating a machine learning model, there are multiple design options as to how to define the model architecture. Usually, exploring a range of possibilities or probabilities helps decide the optimal model architecture. For a machine learning model to learn aptly, it is better to ask the machine to perform this exploration and automatically select the optimal model architecture.
Parameters, which define the model architecture, are referred to as hyperparameters. Thus, this process of searching for the ideal model architecture and thus, the hyperparameter, is referred to as “hyperparameter tuning”.
For example, the weights learned while training a linear regression model are parameters, but the learning rate in gradient descent is a hyperparameter.
The performance of a model on a dataset significantly depends on the proper tuning, i.e., finding the best combination of the model hyperparameters.
Examples of hyperparameters
Some examples of hyperparameters in machine learning are as follows:
- The k in KNN or K-Nearest Neighbour algorithm
- Learning rate for training a neural network
- Number of Epochs. One Epoch is equivalent to one cycle for training a machine learning model. The number of epochs keeps increasing until the validation error reduces.
- Branches in Decision Tree
Importance of hyperparameters
Hyperparameter tuning is quite important while training a machine learning model.
The hyperparameter tuning addresses model design with questions such as:
- What degree of polynomial features should I use for my linear model?
- How many trees should I include in my random forest?
- How many neurons should I have in my neural network layer?
- What should be the maximum depth allowed for my decision tree?
Hyperparameters vs parameters
Categorisation of hyperparameters for training machine learning model
Broadly, hyperparameters can be divided into two categories, which are given below:
- Hyperparameters for optimisation
- Hyperparameters for specific models
Hyperparameters for optimisation
The process of selecting the best hyperparameters to use is known as hyperparameter tuning, and the tuning process is also known as hyperparameter optimization. Optimisation parameters are used for optimising the model.
Some of the popular optimization parameters are given below:
- Learning rate: The learning rate is the hyperparameter in optimization algorithms that controls how much the model needs to change in response to the estimated error for each time when the model’s weights are updated. It is one of the crucial parameters while building a neural network, and also it determines the frequency of cross-checking with model parameters. Selecting the optimised learning rate is a challenging task because if the learning rate is very less, then it may slow down the training process. On the other hand, if the learning rate is too large, then it may not optimise the model properly.
- Batch size: To enhance the speed of the learning process, the training set is divided into different subsets, known as a batch.
- Number of Epochs: An epoch can be defined as the complete cycle for training the machine learning model. Epoch represents an iterative learning process. The number of epochs varies from model to model, and various models are created with more than one epoch. To determine the right number of epochs, a validation error is taken into account. The number of epochs is increased until there is a reduction in a validation error. If there is no improvement in reduction error for the consecutive epochs, then it indicates to stop increasing the number of epochs.
Hyperparameters for specific models
Hyperparameters that are involved in the structure of the model are known as hyperparameters for specific models. These are given below:
- A number of hidden units: Hidden units are part of neural networks, which refer to the components comprising the layers of processors between input and output units in a neural network.
It is important to specify the number of hidden units in the hyperparameter for the neural network. It should be between the size of the input layer and the size of the output layer. More specifically, the number of hidden units should be 2/3 of the size of the input layer, plus the size of the output layer.
For complex functions, it is necessary to specify the number of hidden units, but it should not overfit the model.
- Number of layers: A neural network is made up of vertically arranged components, which are called layers. There are mainly input layers, hidden layers, and output layers. A 3-layered neural network gives a better performance than a 2-layered network. For a Convolutional Neural network, a greater number of layers, ideally 5-7, make a better model.
How to tune hyperparameters?
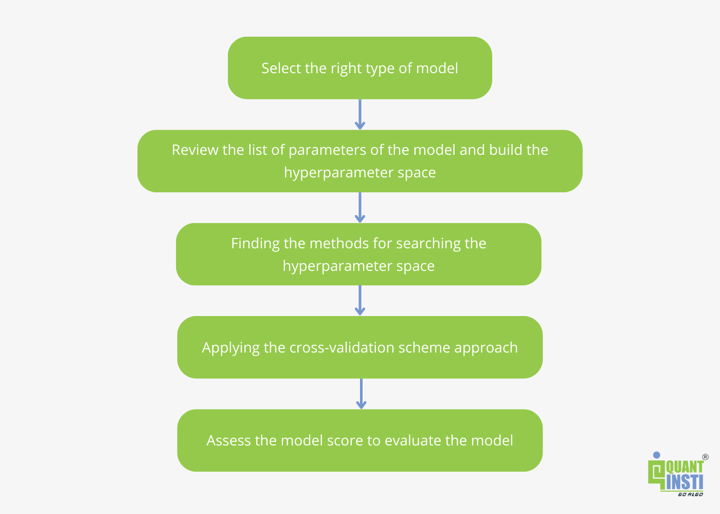
For training the machine learning model aptly, tuning the hyperparameters is required. Following are the steps for tuning the hyperparameters:
- Select the right type of model
- Review the list of parameters of the model and build the hyperparameter space
- Finding the methods for searching the hyperparameter space
- Applying the cross-validation scheme approach
- Assess the model score to evaluate the model
Now, let us see the two most commonly used techniques for hyperparameters tuning. These two techniques are:
- Grid search
- Randomised search
Grid search
Grid search is the technique of exhaustively searching through every combination of the hyperparameter values specified.
Grid search is the simplest algorithm for hyperparameter tuning. Basically, we divide the domain of the hyperparameters into a discrete grid. Then, we try every combination of values of this grid, calculating some performance metrics using cross-validation.
The point of the grid that maximises the average value in cross-validation is the optimal combination of the hyperparameters values.
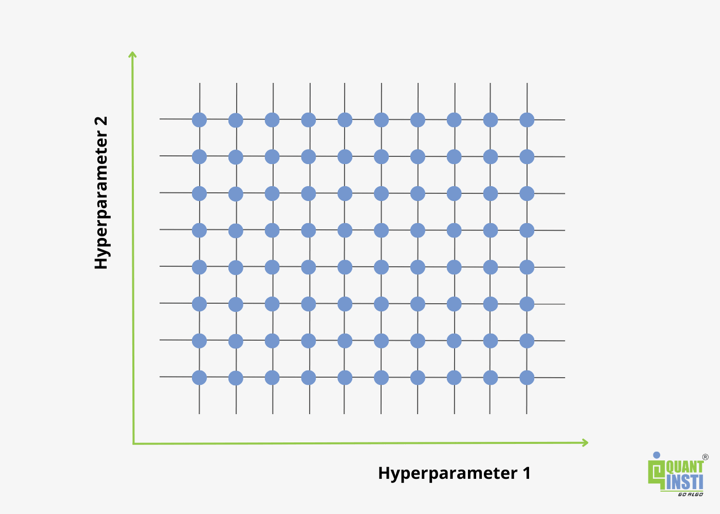
Grid search is an exhaustive algorithm that spans all the combinations, so it can actually find the best point in the domain. One drawback is that it’s very slow. Checking every combination of the space requires a lot of time that, sometimes, is not available.
Every point in the grid needs k-fold cross-validation, which requires k training steps. So, tuning the hyperparameters of a model in this way can be quite complex and expensive. However, if we look for the best combination of values of the hyperparameters, grid search is a very good idea.
Randomised search
In case of randomised search, unlike grid search, not all given parameter values are tried out.
Hence, a fixed number of parameter settings is sampled from the specified distribution of values.
For each hyperparameter, either a distribution of possible values or a list of discrete values (to be sampled uniformly) can be specified.
The process of sampling in a randomised search can be specified beforehand. For each hyperparameter, either a distribution over possible values or a list of discrete values (to be sampled uniformly) can be specified.
The smaller this subset, the faster but less accurate the optimization. The larger this dataset, the more accurate the optimisation but the closer to a grid search.
Random search is a very useful option when you have several hyperparameters with a fine-grained grid of values.
Using a subset made by 5-100 randomly selected points, we are able to get a reasonably good set of values of the hyperparameters.
It will not likely be the best point, but it can still be a good set of values that gives us a good model.
Conclusion
Hyperparameters and hyperparameter tuning are quite important to ensure that the machine learning model stores the correct information for mapping the inputs with the right outputs.
With the right knowledge with regard to hyperparameters, one can train the machine learning model for the required actions.
We discussed the basics of hyperparameters with some examples in this blog and briefly about the parameters, to begin with.
Moreover, we discussed how hyperparameter tuning takes place along with the two most popular techniques for hyperparameter tuning.
This course on machine learning and deep learning helps one understand how different machine learning algorithms can be implemented in financial markets by creating your own prediction algorithms using classification and regression techniques. Do feel free to check it out.
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.
Originally posted on QuantInsti blog.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.