













Part I in this series provides and overview of spaCy and demonstrates how to install the library.
Split text into sentences using spaCy
# Initialize the text that you want to analyze
text = "Ripple was founded in 2012 by Jed McCaleb and Chris Larsen (co-founder of E-Loan). But the gears were in motion back in 2004, four years before Bitcoin, when a Canadian programmer, Ryan Fugger, developed RipplePay.RipplePay, though not based on blockchain, was a secure payment system for a financial network. In 2012, Jed McCaleb and Chris Larsen started the company OpenCoin, renamed Ripple Labs in 2013."
text
# Source: https://blog.quantinsti.com/ripple-xrp/show_text.py hosted with ❤ by GitHubSource: Exploring Ripple and XRP: What it is, Features, and MoreLet us now pass this text to our model and split it into individual sentences.
doc = nlp(text)
# Split the text into sentences
sentences = [sentence.text for sentence in doc.sents]
# Print the original text
print(f"Original text: \n\n{text}\n{'-'*50}\n")
# Print the different sentences from the text
print(
f"We have split the above into {len(sentences)} sentences:\n\n 1. {sentences[0]}\n2. {sentences[1]}")split_the_text.py hosted with ❤ by GitHubRemoving punctuation using spaCy
Before we proceed further with our analysis, let us remove the punctuations from our text.
token_without_punc = [token for token in doc if not token.is_punct]
token_without_puncremove_punctuation.py hosted with ❤ by GitHubRemoving stop words using spaCy
We can remove the stop words like and, the, etc. from the text because these words don’t add much value to it for analysis purposes.
For this, we first get the list of all the stop words for that language. There are two ways in which we can do it.
# Get the stop words: 1st method
all_stopwords = nlp.Defaults.stop_words
len(all_stopwords) # Output: 326remove_stop_words.py hosted with ❤ by GitHubThis is the second method.
# Get the stop words: 2nd method
from spacy.lang.en.stop_words import STOP_WORDS
len(STOP_WORDS) # Output: 326remov_stop_words_2nd_method.py hosted with ❤ by GitHubAs we can see from the code below, the results of both the above methods are the same.
# Both are the same
all_stopwords is STOP_WORDScheck_methods_equality.py hosted with ❤ by GitHubNow that we have got the list of stop words, let’s remove them from our text.
# Remove the stop words
token_without_stop = [
token for token in token_without_punc if not token.is_stop]
token_without_stopremove_stop_words_from_text.py hosted with ❤ by GitHubPOS tagging using spaCy
Let us now see how spaCy tags each token with its respective part-of-speech.
import pandas as pd
token_pos = []
for token in token_without_punc:
token_pos.append([token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop])
df = pd.DataFrame(token_pos, columns=['Text', 'Lemma', 'POS', 'Tag',
'Syntactic dependency relation', 'Shape', 'Is Alphabet', 'Is stop word'])
dfpos_tagging.py hosted with ❤ by GitHubIf you would like to know more about the different token attributes, please click here.
Named entity recognition using spaCy
What is a named entity? It is any ‘real-world object’ with an assigned name. It may be a country, city, person, building, company, etc. spaCy models can predict the different named entities in a text with remarkable accuracy.
ner = []
for ent in doc.ents:
ner.append([ent.text, ent.start_char, ent.end_char, ent.label_])
df_ner = pd.DataFrame(
ner, columns=['Text', 'Start character', 'End character', 'Label'])
df_nernamed_entity.py hosted with ❤ by GitHubDependency Visualization using displaCy
Adding another powerful functionality to it’s arsenal, spaCy also comes with a built-in dependency visualizer valled displaCy that lets you check your model’s predictions in your browser.
To use it from the browser, we use the ‘serve’ method. DisplaCy can auto-detect if you are working on a Jupyter notebook. We can use the ‘render’ method to return markup that can be rendered in a cell.
Let us try the spaCy’s entity visualizer to render the NER results we got above.
For this, let us import displaCy which is ‘a modern and service-independent visualisation library’
from spacy import displacy
displacy.render(doc, style="ent")dependency_visualisation.py hosted with ❤ by GitHubOutput:

Getting linguistic annotations using spaCy
You can get insights into the grammatical structure of a text using spaCy’s linguistic annotations functionality. It basically tells you the part of speech each word belongs to and how the different words are related to each other.
We need to have installed spaCy and the trained model that we want to use. In this blog, we’ll work with the English language model, the en_core_web_sm.
Let’s look at an example.
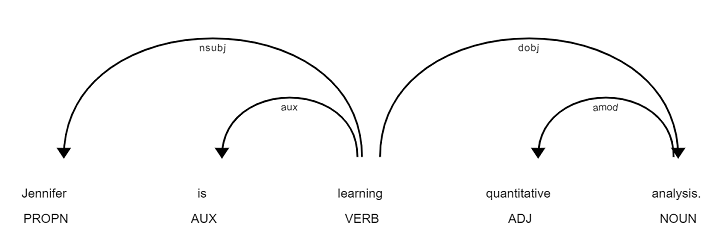
# Pass the text you want to analyze to your model
doc = nlp("Jennifer is learning quantitative analysis.")
# Print the part-of-speech and the syntactic dependency relation for the tokens
for token in doc:
print(token.text, token.pos_, token.dep_)linguistic_annotations.py hosted with ❤ by GitHubLet’s visualize the syntactic relationship between the different tokens.
from spacy import displacy
displacy.render(doc, style="dep")visualise_syntactic_relationship.py hosted with ❤ by GitHubOutput:
spaCy examples on Github
We’ve covered some of the basic NLP techniques using the spaCy library. To delve into further details, you can head to the spaCy GitHub page where you can find tons of examples to help you in your journey into the spaCy universe.
In addition to the development techniques, you can also try out the extensive test suite offered by spaCy which uses the pytest framework.
Conclusion
We’ve explored some of the main features of spaCy, but there is a lot more to be explored in this powerful Python natural language processing library. I hope that this blog has gotten you started with the initial few steps of this journey. So go ahead and explore the enormous world of human language and thoughts!
Want to harness alternate sources of data, to quantify human sentiments expressed in news and tweets using machine learning techniques? Check out this course on Trading Strategies with News and Tweets. You can use sentiment indicators and sentiment scores to create a trading strategy and implement the same in live trading.
Till then, happy tweeting and Pythoning!
Visit QuantInsti website for additional insight on this topic: https://blog.quantinsti.com/spacy-python/.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.