














Background
Python’s pymining package provides a collection of useful algorithms for item set mining, association mining, and more. We’ll explore some of its functionality during this post by using it to apply basket analysis to tennis. When basket analysis is discussed, it’s often in the context of retail – analyzing what combinations of products are typically bought together (or in the same “basket”). For example, in grocery shopping, milk and butter may be frequently purchased together. We can take ideas from basket analysis and apply them in many other scenarios.
As an example – let’s say we’re looking at events like tennis tournaments where each tournament has different successive rounds i.e. quarterfinals, semifinals, finals etc. How would you figure out what combinations of players typically show up in the same rounds i.e. what combinations of players typically appear in the semifinal round of tournaments? This is effectively the same type question as asking what combinations of groceries are typically bought together. In both scenarios we can use Python to help us out!
The data I’ll be using in this post can be found by clicking here (all credit for the data goes to Jeff Sackmann / Tennis Abstract). It runs from 1968 through part of 2019.
Prepping the data
First, let’s import the packages we’ll need. From the pymining package, we’ll import a module called itemmining.
from pymining import itemmining import pandas as pd import itertools import os
Next, we can read in our data, which sits in a collection of CSV files that I’ve downloaded into a directory from the link above. Our analysis will exclude data from futures and challenger tournaments, so we need to filter out those files as seen in the list comprehension below.
# set directory to folder with tennis files
os.chdir("C:/path/to/tennis/files")
# get list of files we need
files = [file for file in os.listdir() if "atp_matches" in file]
files = [file for file in files if "futures" not in file and "chall" not in file]
# read in each CSV file
dfs = []
for file in files:
dfs.append(pd.read_csv(file))
# combine all the datasets into a single data frame
all_data = pd.concat(dfs)
The next line defines a list of the four grand slam, or major, tournaments. We’ll use this in our analysis. Then, we get the subset of our data containing only results related to the four major tournaments.
major_tourneys = ["Wimbledon", "Roland Garros", "US Open",
"Australian Open"]
# get data for only grand slam tournaments
grand_slams = all_data[all_data.tourney_name.isin(major_tourneys)]
Combinations of semifinals players
Alright – let’s ask our first question. What combinations of players have appeared the most in the semifinals of a grand slam? By “combination”, we can look at – how many times the same two players appeared in the last four, the same three players appeared, or the same four individuals appeared in the final four.
# get subset with just semifinals data
sf = grand_slams[grand_slams["round"] == "SF"]
# split dataset into yearly subsets
year_sfs = {year : sf[sf.year == year] for year in sf.year.unique()}
Next, we’ll write a function to extract what players made it to the semifinals in a given yearly subset. We do this by splitting the yearly subset input into each tournament separately. Then, we extract the winner_name and loser_name field values in each tournament within a given year (corresponding to that yearly subset).
def get_info_from_year(info, tourn_list):
tournaments = [info[info.tourney_name == name] for name in tourn_list]
players = [df.winner_name.tolist() + df.loser_name.tolist() for df in tournaments]
return players
We can now get a list of all the semifinalists in each tournament throughout the full time period:
player_sfs = {year : get_info_from_year(info, major_tourneys) for
year,info in year_sfs.items()}
player_sfs = [elt for elt in itertools.chain.from_iterable(player_sfs.values())]
Using the pymining package
Now it’s time to use the pymining package.
sf_input = itemmining.get_relim_input(player_sfs) sf_results = itemmining.relim(sf_input, min_support = 2)
The first function call above – using itemmining.get_relim_input – creates a data structure that we can then input into the itemmining.relim method. This method runs the Relim algorithm to identify combinations of items (players in this case) in the semifinals data.
We can check to see that sf_results, or the result of running itemmining.relim, is a dictionary.
type(sf_results) # dict
By default, itemmining.relim returns a dictionary where each key is a frozenset of a particular combination (in this case, a combination of players), and each value is the count of how many times that combination appears. This is analogous to the traditional idea of basket analysis where you might look at what grocery items tend to be purchased together, for instance (e.g. milk and butter are purchased together X number of times).
The min_support = 2 parameter specifies that we only want combinations that appear at least twice to be returned. If you’re dealing with large amounts of different combinations, you can adjust this to be higher as need be.
{key : val for key,val in sf_results.items() if len(key) == 4}
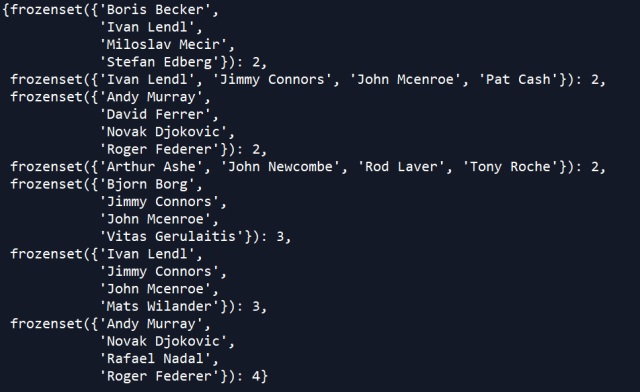
From this we can see that the “Big 4” of Federer, Nadal, Djokovic, and Murray took all four spots in the semifinals of grand slam together on four separate occasions, which is more than any other quartet. We can see that there’s two separate groups of four players that achieved this feat three times.
Let’s examine how this looks for groups of three in the semifinals.
three_sf = {key : val for key,val in sf_results.items() if len(key) == 3}
# sort by number of occurrences
sorted(three_sf.items(), key = lambda sf: sf[1])

Above we can see that the the top three most frequent 3-player combinations are each subsets of the “big four” above – with Federer, Nadal, and Djokovic making up the top spot. We can do the same analysis with 2-player combinations to see that the most common duo appearing in the semifinals is Federer / Djokovic as there have been 20 occasions where both were present in the semifinals of the same major event.

The most number of times a single duo appeared in the semifinals outside of Federer / Nadal / Djokovic / Murray is Jimmy Connors / John McEnroe at 14 times.
Analyzing semifinals across all tournaments
What if we adjust our analysis to look across all tournaments? Keeping our focus on the semifinal stage only, we just need to make a minor tweak to our code:
# switch to all_data rather than grand_slams
sf = all_data[all_data["round"] == "SF"]
year_sfs = {year : sf[sf.year == year] for year in sf.year.unique()}
player_sfs = {year : get_info_from_year(info, all_data.tourney_name.unique()) for
year,info in year_sfs.items()}
player_sfs = [elt for elt in itertools.chain.from_iterable(player_sfs.values())]
sf_input = itemmining.get_relim_input(player_sfs)
sf_results = itemmining.relim(sf_input, min_support = 2)
# get 2-player combinations only
{key : val for key,val in sf_results.items() if len(key) == 2}

Here, we can see that Federer / Djokovic and Djokovic / Nadal have respectively appeared in the semifinals of a tournament over 60 times. If we wanted to, we could also tweak our code to look at quarterfinal stages, earlier rounds, etc.
Lastly, to learn more about pymining, see its GitHub page here.
Originally posted on TheAutomatic.net Blog.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from TheAutomatic.net and is being posted with its permission. The views expressed in this material are solely those of the author and/or TheAutomatic.net and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.