
















This post will cover two different ways to extract dates from strings with Python. The main purpose here is that the strings we will parse contain additional text – not just the date. Scraping a date out of text can be useful in many different situations.
Option 1) dateutil
The first option we’ll show is using the dateutil package. Here’s an example:
from dateutil.parser import parse
parse("Today is 12-01-18", fuzzy_with_tokens=True)
Above, we use a method in dateutil called parse. The first parameter to this method is the string of the text we want to use to search for a date. The second parameter, fuzzy_with_tokens, is set equal to True – this causes the method to return where the date is found in the string. In other words, in the string above, the date is found after the substring “Today is “, which is specified in the tuple output. If we want to get just the returned datetime object, we can do this:
result = parse("Today is 12-01-18", fuzzy_with_tokens=True)
# get just the datetime object
result[0]Let’s see how much we can vary a particular date:
parse("Today is December 1, 2018", fuzzy_with_tokens=True)
parse("Today is Dec 1 2018", fuzzy_with_tokens=True)
parse("Today is Dec 1", fuzzy_with_tokens=True)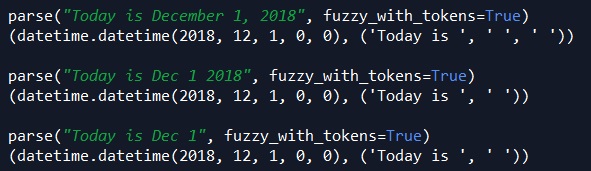
In the third line of code above, we don’t specify the year. Here, dateutil assumes by default the year associated with the date is the current one (2018).
If we follow up the last example above of Dec 1 with the two-digit abbreviation of a year, dateutil is good enough to figure that out:
parse("Today is Dec 1 16", fuzzy_with_tokens=True)
parse("Today is Dec 1 14", fuzzy_with_tokens=True)
parse("Today is Nov 30 12", fuzzy_with_tokens=True)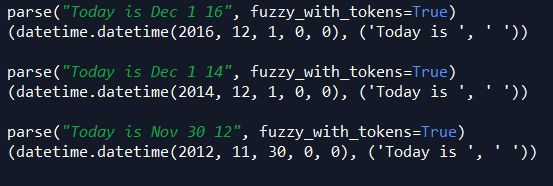
In the string below, we leave off the year and month, and just say “on the 14th.” In this case, dateutil will assume the month and year are the current month and year, but will parse out the day from the string (in this case, the 14th).
parse("on the 14th", fuzzy_with_tokens=True)
What if we want to pass a string that has multiple dates?
parse("The next one will be on 12-02-18 or 12-03-18", fuzzy_with_tokens=True)By default, the parse method will only return the first date found in the string.

We could tinker with the method and write some additional code to handle multiple dates in a string, but there is an alternative in the dateparser package.
Option 2) Extract dates from strings with Python & dateparser
The dateparser package comes with an option to search for dates in a string, using a method called search_dates.
from dateparser.search import search_dates
search_dates("find 12/15/18 in this string")
search_dates also returns a tuple result, except that the first element of this result is the actual substring identified as a datetime.
Next, if we do the example we did above with dateutil we get back two results. This is because dateparser is flagging the word “today” as a reference to a date, as well as finding the date “12-01-18.”
search_dates("Today is 12-01-18")
Likewise, the examples below also identify the word “today” as today’s date, while capturing variations of the date “December 1, 2018.”
search_dates("Today is December 1, 2018")
search_dates("Today is Dec 1 2018")
search_dates("Today is Dec 1")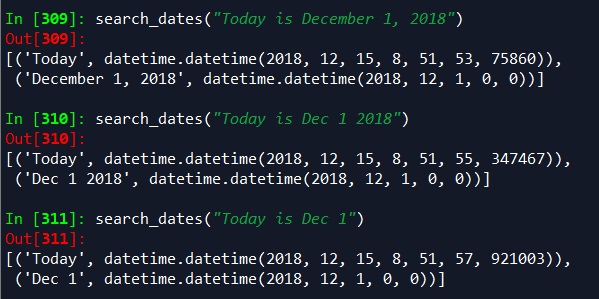
A few more examples like above:
search_dates("Today is Dec 1 16")
search_dates("Today is Dec 1 14")
search_dates("Today is Nov 30 12")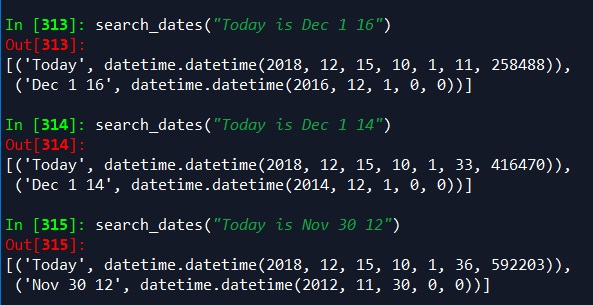
Because search_dates tells us what substring is matched to a datetime, we could exclude results matching to “today” like this:
results = search_dates("Today is December 1, 2018")
need = [result for result in results if result[0].tolower() != "today"]Here we just use a list comprehension to filter the datetime results to those that don’t match to the word “today.”
What if we want to search a longer piece of text? For example, let’s suppose we want to search the Wikipedia page on Python for all the appearing datetimes.
# load additional packages
from bs4 import BeautifulSoup
import requests
# get HTML content / BeautifulSoup object
resp = requests.get("https://en.wikipedia.org/wiki/Python_(programming_language)")
soup = BeautifulSoup(resp.content)
# search for all paragraphs on the webpage
paragraphs = soup.find_all("p")
# get the text for each paragraph
text = [x.text for x in paragraphs]
# scrape any dates from each paragraph
results = []
for paragraph in text:
try:
results.append(search_dates(paragraph))
except Exception:
passNow results contains a list of the datetimes that appear in the Wikipedia page text. We can get a count of how many datetimes were found using the below code:
counts = [0 if result is None else len(result) for result in results]
sum(counts)Above, we use a list comprehension again. This time, we loop through the datetime results, giving a count of zero if None is returned for a given paragraph (i.e. if no datetime is found in a paragraph); otherwise the number of datetimes gets returned and stored in the list, counts. Summing the counts variable tells us the total number of datetimes found by searching through all the paragraphs on the webpage. In this case, there are 71.

Conclusion
In this post we covered how to extract dates from strings with Python. For more on working with dates, check out this post for standardizing dates with Python.
See my other Python posts by clicking here.
Visit TheAutomatic.net to learn more about this topic.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from TheAutomatic.net and is being posted with its permission. The views expressed in this material are solely those of the author and/or TheAutomatic.net and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.