














This post is intended to be the first of a multi-part series on Bayesian statistics and methods in quantitative finance. My write up here is a short introductory post that went rogue.
Motivation
I must confess that when I first encountered the Bayesian approach to inferential statistics in my formal education, it was tough going. The material I read and the teachers who taught me were excellent but it took months before I could fully appreciate them. I spent countless hours trawling through the internet (blogs, websites, online forums, etc.) and other traditional sources (books & academic journals) trying to build a fundamental understanding of this subject. I managed to get there eventually. My aim here is primarily, to help you, the reader, learn from my missteps. This entire series attempts to provide an intuitive feel for Bayesian statistics and its applications without getting too caught up in the scary math. We are dealing with an exciting and challenging subject so I must warn you that it will demand of you both effortful thinking and hard work. My secondary aim is to stave off (at least for a little while) the question asked of me by colleagues, friends and family – “When will you be done writing?” If these posts pique your curiosity to explore further, a lot of good stuff is available both in print and on the web with varying levels of complexity. I will point you to some of these resources in the coming posts.
Who Should Read This?
The main prerequisite for understanding these notes is some exposure to probability theory and statistics. I seek to introduce Bayesian statistics in an accessible way to readers who have some conversance with classical statistical analysis (which is mostly any kind of inferential analysis you may have studied so far unless stated otherwise). I have tried to find a middle ground between scientific rigour where theorems are proved and a purely empirical approach dictated by observations and analysis minus any theorems. I hope that readers are comfortable with some of the concepts I have listed below. If a number of them are unfamiliar to you, I would recommend you acquaint yourself with some of them to profit from the time and effort you invest here. This glossary can give you a once-over if you are looking for something quick and dirty. An overview of these ideas should suffice; you do not need exceptional mathematical sophistication. The ideas will get clearer as you work with them here and elsewhere.
Continuous and Discrete Random Variables; Distributions; Expected Value; Variance: Probability Distribution Function (PDF); Probability Mass Function (PMF); Maximum Likelihood Estimation (MLE); Bayes’ Theorem; Conditional Probability; Marginal Probability; Bernoulli, Binomial, Normal, Gaussian, Gamma, Beta, Student-t distribution; Population; Sample; Sample Mean; Sample Variance; Population Mean; Population Variance; Covariance and Correlation.
I would urge you to pick up a pencil and paper to work out the derivations or exercises that crop up through this series. I sometimes don’t spell out every step of the way. So it will help you both, fill in any missing details, and sharpen your own understanding of the topic.
Intent of this Post
In this post, I set the stage for our grand endeavour by providing a gentle introduction to Bayesian statistics, a branch of statistical analysis founded on Bayes’ Theorem. I contextualize it by first covering some ground on the two main schools of thought in statistical analysis viz. the frequentist and the Bayesian. I then proceed to establish how the differences between them impact their respective philosophical styles. Once we do this, I pick an example to get us comfortable with the Bayesian approach to probabilistic problems. I conclude my article with stating Bayes’ Theorem and display its formal use with another example. My presentation of example, theorem, example is by design. This should hopefully help us make the connection between the illustrations and the underlying principles they embody. Let’s get started.
Laying Out the Context
Imagine a scenario where a data scientist or an economic researcher has collected data about a phenomenon that she is studying. This data may be collected by observing a number of subjects at a certain point in time (cross-sectional data) or by observing a subject over a number of time periods (time-series data). It could also be a combination of cross-sectional and time-series observations i.e. observing a number of subjects tracked over multiple time periods (panel data). In econometric studies, these subjects are usually individuals, firms, regions, or countries and the time-periods are yearly, quarterly, daily or higher frequencies. In quantitative finance, we typically track the movements of different asset classes through time. A short excursion: The data that econometricians (I use this as a motley term to include quantitative analysts, financial economists, empirical economic/financial researchers and even some data scientists) work with are almost always observational. This is fundamentally different from the data generated via controlled experiments in many of the pure and applied sciences (like medicine, physics, engineering, etc.). Coming back to the main story, a key choice that our researcher would need to make is the approach to statistical inference i.e. using frequentist statistics or Bayesian statistics. This is an important choice point and a good place to tee off on our journey. I now proceed to compare and contrast classical (frequentist) statistics and Bayesian statistics in drawing inferences.
The Philosophical Background
Statistical analysis and the subsequent inferences we draw from it are based on probability theory. The way in which probability is defined and interpreted has created two schools of statistical thought, viz. frequentist statistics and Bayesian statistics. The frequentist worldview (also called the classical or traditional approach) refers to the philosophical approach of Ronald Fisher. It views the probability of an event as the long run frequency of occurrence of that event (hence the name). We would, therefore, measure the probability of that event as the frequency at which it occurs after repeating the experiment ad infinitum. However, this is not always possible in practice. For instance, if we want to compute what the probability of a global recession occurring in the coming year is, we do not have a large sample of data available since we only have reliable economic data for about a century or so. In cases like these, frequentists use theoretical results and techniques to arrive at the probability of occurrence. I’ll elaborate a little more on this as we move along. So in summary, for frequentists, the probability is inextricably tied to the long run frequency of occurrence of events. The Bayesian (named after its discoverer Thomas Bayes) worldview of probability is more visceral. It interprets probability as a subjective opinion i.e. it is a measure of belief or plausibility that we have of an event occurring. We update our opinions (as measured by probability) as and when we receive more information. Simply put, for Bayesian decision makers, the probability is a statement of an individual subjective opinion. While I do highlight the subjective nature quality of our definition here, I must hasten to add that the axioms of probability still need to be satisfied. This philosophy of quantifying our beliefs or opinions as a probability comes quite naturally to us. One of the basic principles of learning is to assimilate the information that arrives from the external environment and update our extant knowledge (what we casually refer to as common sense) with this newly acquired information. This is the kernel of the Bayesian worldview which animates the Bayesian statistics enterprise. This is also how we operate in the real world where we form beliefs (and by extension, assign probabilities) based on what we know. Let’s say we assign a certain probability to a particular candidate winning the elections six months from now. As time passes by, we would continually update our beliefs or opinions (as measured by the probability of the candidate winning) based on news reports, opinion polls, etc. so as to reflect the changing realities. The divide between frequentists and Bayesians is fundamentally one of philosophy which I show has wider ramifications in their differing approaches to statistical analysis.
Frequentist v/s Subjective Probabilities
One of the enduring controversies in probability theory is about the type of events where probabilities (in the frequentist sense) can be defined. I had briefly alluded to it earlier in a case where the experiment could not be performed repeatedly. As per the frequentist definition, the only situations where probabilities hold any meaning are those where we examine the relative frequency of occurrences of an event as the number of observations tends to infinity i.e.

where k is the number of occurrences of the event and n is the number of repetitions of the experiment. This method of assigning probabilities creates two issues. First, even in cases where the experiment is recurrent, it requires us to conduct the experiment an infinite number of times which is impossible. The second is a more serious issue. We are unable to assign probabilities to events which are not the outcomes of repeated experiments. This would not please the Bayesians among us who take a more subjective view of probability. They view probability as a reflection of their uncertainty about the state of the world. The way they see it, probability and uncertainty are tautological. A Bayesian decision maker would assign probabilities to the outcomes of repeated experiments and also to statements about the winner of the next national election (i.e. the outcome of a non-recurrent experiment). I linger on these differences and flesh it out a little more in the following section.
The Devil is in the Details
The frequentist approach has a different take on uncertainty. In this world, uncertainty stems only from the randomness that is implicit in the realizations of any experiment or phenomenon. In other words, the data generated would be random or uncertain, however, the underlying phenomenon studied is fixed but unknown. In contrast, the Bayesian researcher notes from her first principles, an inherent uncertainty in the phenomenon being studied. She expresses this doubt before commencing her study based on her existing knowledge and calls it the prior probability. Once she completes her study of the phenomenon, she incorporates this knowledge (this is data in statistics-speak) to update her own subjective beliefs and calls it the posterior probability. I now depict an illustration to get a flavour of the Bayesian way of thinking. Once we are familiar with this, I conclude our learning for this post with a postulation of Bayes’ Theorem alongside an application in inferential statistics.
Example 1
Consider a scenario as shown below:
- A mobile phone manufacturer has three different plants which manufacture them.
- 50% of the phones come from plant 1, 30% come from plant 2 and the remaining from plant 3.
- 10% of the phones from plant 1 are defective, similarly, 20% from plant 2 and 25% from plant 3 are defective.
Suppose we find a defective phone and want to know the likelihood that it came from plant 1. One way to go about solving this is to initially assume there are a total of 100 phones. We can then make the following statements based on what we know.
- 50 phones would come from plant 1; 10% of these are defective, so we work out that 5 would be defective; the remaining 45 would be non-defective.
- Similarly, 30 phones come from plant 2; 6 would be defective and ∴ 24 would be non-defective.
- And, 20 phones come from plant 3; 5 would be defective, ∴ 15 would be non-defective.
We can see that a total of 16 phones are defective out of which 5 are from plant 1. Let us tabulate our results for clarity.
| Plant | # of Phones Produced | # of Defective Phones | # of Non-Defective Phones |
|---|---|---|---|
| 1 | 50 | 5 | 45 |
| 2 | 30 | 6 | 24 |
| 3 | 20 | 5 | 15 |
∴∴ the likelihood of a defective phone being manufactured in plant 1 is 5/16.
The Theorem
I now use the following notations to frame our problem statement using Bayes’ Theorem. Let AA be the event that the phone is defective, Bi be the event that the phone was manufactured in plant i, and P(⋅) denote the probability. I also use the conventional notation for conditional probability, P(⋅|⋅). Without loss of generality, Bayes’ Theorem for our example can be algebraically expressed as:
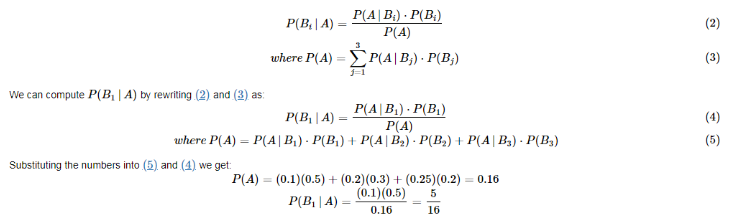
Our instinctive approach earlier is consistent with the application of Bayes’ theorem as seen above. What makes this theorem so handy is it allows us to invert a conditional probability. I now employ a simple illustration to demonstrate how Bayes’ theorem can be used in an inferential setting.
Visit QuantInsti to read the full article: https://blog.quantinsti.com/introduction-to-bayesian-statistics-in-finance/.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.