













See Part I, Part II and Part III to get started.
In case 2, we will repeat the above process, but with a much larger sample size (n=500):
# drawing 50 random samples of size 500
sample_size=500
df500 = pd.DataFrame()
for i in range(1, 51):
exponential_sample = np.random.exponential((1/rate), sample_size)
col = f’sample {i}’
df500[col] = exponential_sample
df500_sample_means = pd.DataFrame(df500.mean(),columns=[‘Sample means’])
sns.distplot(df500_sample_means);
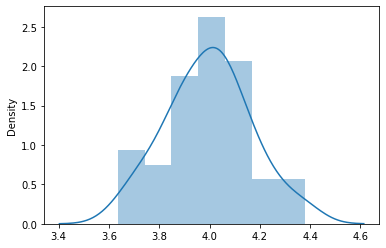
The sampling distribution looks much more like a normal distribution now as we have sampled with a much larger sample size (n=500).
Let us now check the mean and the standard deviation of the 50 sample means:
#The first 5 values from the 50 sample means
df500_sample_means.head()
| Sample means | |
| sample 1 | 4.061534 |
|---|---|
| sample 2 | 4.052322 |
| sample 3 | 3.823000 |
| sample 4 | 4.261559 |
| sample 5 | 3.838798 |
We can observe that the mean of all the sample means is quite close to the population mean (μ=4)(μ=4).
Similarly, we can observe that the standard deviation of the 50 sample means is quite close to the value stated by the CLT, i.e., (σ/√n)(σ/n) = 0.178.
# An estimate of the mean of the sampling distribution can be obtained as:
np.mean(df500_sample_means).values[0]
0.18886796530269118
# The above value is very close to the value stated by the CLT, which is:
sd/ np.sqrt(sample_size)
0.17888543819998318
Thus, we observe that the mean of all sample means is very close in value to the population mean itself. Also, we can observe that as we increased the sample size from 2 to 500, the distribution of sample means increasingly starts resembling a normal distribution, with mean given by the population mean μμ and the standard deviation given by (σ/√n)(σ/n), as stated by the Central Limit Theorem.
Stay tuned for the next installment, in which Ashutosh will go over the code for binomially distributed population.
Visit QuantInsti for additional details and to download full code: https://blog.quantinsti.com/central-limit-theorem/.
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.