









![[Gamma] Scalping Please](https://ibkrcampus.com/wp-content/smush-webp/2024/04/tir-featured-8-700x394.jpg.webp "[Gamma] Scalping Please")




Natural Language Processing or NLP is used extensively in trading. It is mainly used to gauge the sentiment of the market through Twitter feeds, Newspaper Articles, RSS feeds and Press releases. In this blog, we will cover the basic structure needed to solve the NLP problem from a trader’s perspective.
Trading and NLP
Anyone who has traded some sort of a financial instrument knows that the markets constantly factor in all the news that is pouring in through various sources.
The cause and effect relationship between impactful news and market movements can be directly observed when one tries to trade the market during the release of big news such as the non-farm payrolls data.
News and NLP
Before social media became one of the main sources of information, traders used to depend on the Radio or TV announcements for the latest information.
But since Twitter became a source of market-moving news (thanks to political leaders), traders are finding it difficult to manually track all the information originating from different Twitter handles. To circumvent this problem, traders can use NLP packages to read multiple news sources in a short amount of time and make a quick decision.
If you are a trader, then you should definitely learn how to use NLP in trading to outperform other traders. Now I am going to list out in a step by step manner how you can approach the problem of using NLP in trading and discuss each of them in detail.
Steps for using NLP in trading
The following are the steps that one needs to follow for using NLP for Trading:
- Get the data
- Preprocess the data
- Convert the text to a sentiment score
- Generate a trading model
- Backtest the model
Get the data
To build an NLP model for trading, you need to have a reliable source of data. There are multiple vendors for this purpose.
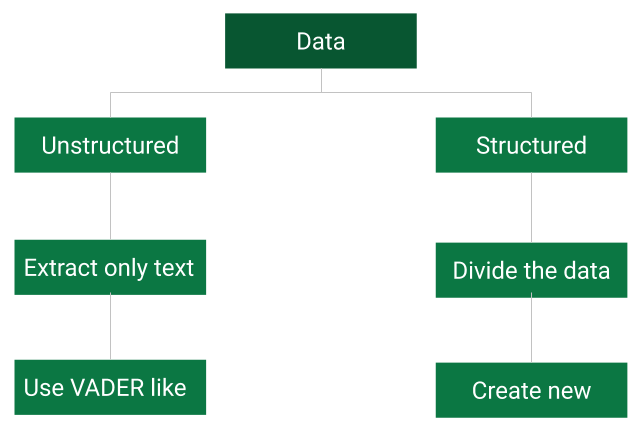
For example, Twitter and Webhose provide it for free, while others such as News API, Reuters and Bloomberg will charge you for it. Let us divide the data into two types and try to approach each of them differently.
Structured data is one that is published in a predetermined or consistent format. The language is also very consistent.
For example, the press release of Fed minutes or a company’s earnings can be considered as structured data. Here the length of the text is usually very huge.
On the contrary, unstructured data is one where neither the language or format is consistent. For example, Twitter feeds, blogs and articles can be counted as a part of this. These texts are usually limited in size.
In part II, Varun will show us how to preprocess the data and convert the text to a sentiment score.
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from QuantInsti and is being posted with its permission. The views expressed in this material are solely those of the author and/or QuantInsti and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.