









![[Gamma] Scalping Please](https://ibkrcampus.com/wp-content/smush-webp/2024/04/tir-featured-8-700x394.jpg.webp "[Gamma] Scalping Please")




The Alpha Scientist demonstrates the Relative Importance of Features. See the previous installment in this series to learn about Multivariate Effects.
Relative Importance of Features
With so many findings, where do we start? I’ll run a quick random forest regression model and test the relative significance of each hyperparameter in overall model performance:
In [70]:
from sklearn.preprocessing import MinMaxScaler
X = df[[‘first_neuron’,’hidden_neuron’,’hidden_layers’,’dropout’]]
scaler = MinMaxScaler()
y = scaler.fit_transform(df[[‘val_loss_improvement’]])
from sklearn.ensemble import RandomForestRegressor
reg = RandomForestRegressor(max_depth=3,n_estimators=100)
reg.fit(X,y)
pd.Series(reg.feature_importances_,index=X.columns).\
sort_values(ascending=True).plot.barh(color=’grey’,title=’Feature Importance of Hyperparameters’)
Out [70]:
<matplotlib.axes._subplots.AxesSubplot at 0x7f4231951710>
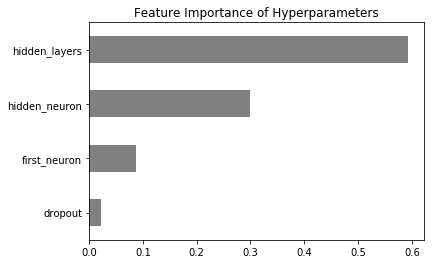
It appears that number of hidden layers is – by far – most important, followed by size of hidden layers. Of course, if we drop to zero hidden layers, then first layer size become supremely important.
For the next hyperparameter sweep, I’ll focus on larger layer sizes – and fewer layers.
In [2]:
## Experiment 2:
from keras.models import Sequential
from keras.layers import Dropout, Dense
from keras.callbacks import TensorBoard
from talos.model.early_stopper import early_stopper
# track performance on tensorboard
tensorboard = TensorBoard(log_dir=’./logs’,
histogram_freq=0,batch_size=10000,
write_graph=False,
write_images=False)
# (1) Define dict of parameters to try
p = {‘first_neuron’:[100,200,400,800,1600,3200],
‘hidden_neuron’:[100, 200, 400, 800 ],
‘hidden_layers’:[0,1],
‘batch_size’: [10000],
‘optimizer’: [‘adam’],
‘kernel_initializer’: [‘uniform’], #’normal’
‘epochs’: [100], # increased in case larger dimensions take longer to train
‘dropout’: [0.0,0.25],
‘last_activation’: [‘sigmoid’]}
# (2) create a function which constructs a compiled keras model object
def numerai_model(x_train, y_train, x_val, y_val, params):
print(params)
model = Sequential()
## initial layer
model.add(Dense(params[‘first_neuron’], input_dim=x_train.shape[1],
activation=’relu’,
kernel_initializer = params[‘kernel_initializer’] ))
model.add(Dropout(params[‘dropout’]))
## hidden layers
for i in range(params[‘hidden_layers’]):
print (f”adding layer {i+1}”)
model.add(Dense(params[‘hidden_neuron’], activation=’relu’,
kernel_initializer=params[‘kernel_initializer’]))
model.add(Dropout(params[‘dropout’]))
## final layer
model.add(Dense(1, activation=params[‘last_activation’],
kernel_initializer=params[‘kernel_initializer’]))
model.compile(loss=’binary_crossentropy’,
optimizer=params[‘optimizer’],
metrics=[‘acc’])
history = model.fit(x_train, y_train,
validation_data=[x_val, y_val],
batch_size=params[‘batch_size’],
epochs=params[‘epochs’],
callbacks=[tensorboard,early_stopper(params[‘epochs’], patience=10)], #,ta.live(),
verbose=0)
return history, model
# (3) Run a “Scan” using the params and function created above
t = ta.Scan(x=X_train.values,
y=y_train.values,
model=numerai_model,
params=p,
grid_downsample=1.00,
dataset_name=’numerai_example’,
experiment_no=’2′)
There we have it. Is this optimal? Almost certainly not. But I now have a much better understanding of how the model performs at various geometries – and have spent relatively little time performing plug-and-chug parameter tweaking.
At this point, I’ll build and train a single model with parameter values that showed most successful in the hyperparameter sweeps.
There are infinite possibilities for further optimizations, which I won’t explore here. For instance:
- RELU vs ELU unit types
- Various geometries of topography (funnel-shaped, etc…)
- Initializer type
- Optimizer type
- Feature extraction/selection methods (e.g., PCA)
Visit The Alpha Scientist blog to download the complete code:
https://alphascientist.com/hyperparameter_optimization_with_talos.html
Stay tuned for the next installment in this series to learn more about the Final Model.
The Alpha Scientist blog – Chad is a full-time quantitative trader who has been working on data analytics since before it was cool. He has long balanced his interest in computer science (MS in EE/CS from MIT) with a fascination in markets (CFA designation in 2009). Prior to becoming a full-time quant, he built analytics products and managed teams at software companies across Silicon Valley. If you’ve found this post useful, please follow @data2alpha on Twitter and forward to a friend or colleague who may also find this topic interesting. https://alphascientist.com/
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from The Alpha Scientist and is being posted with its permission. The views expressed in this material are solely those of the author and/or The Alpha Scientist and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.