









![[Gamma] Scalping Please](https://ibkrcampus.com/wp-content/smush-webp/2024/04/tir-featured-8-700x394.jpg.webp "[Gamma] Scalping Please")





Learn which R packages and data sets you need by reviewing Part I, Part II ,Part III, Part IV, Part V , Part VI, Part VII, Part VIII and Part IX of this series.
Plug the optimal parameters into the model.
#################################################################################
################# XGBoost Optimal Parameters from Cross Validation ##############
# This is the final training model where I use the most optimal parameters found over the grid space and plug them in here.
watchlist <- list(“train” = dtrain)
params <- list(“eta” = 0.1, “max_depth” = 5, “colsample_bytree” = 1, “min_child_weight” = 1, “subsample”= 1,
“objective”=”binary:logistic”, “gamma” = 1, “lambda” = 1, “alpha” = 0, “max_delta_step” = 0,
“colsample_bylevel” = 1, “eval_metric”= “auc”,
“set.seed” = 176)
nround <- 95
Now that I have the optimal parameters from the cross validation grid search I can train the final XGBoost model on the whole train_val.csv data set. (Whereas before the optimal parameters were obtained from different folds in the model. More info on k-fold cross validation here)
# Train the XGBoost model
xgb.model <- xgb.train(params, dtrain, nround, watchlist)
## [1] train-auc:0.700790
## [2] train-auc:0.720114
## [3] train-auc:0.735281
## [4] train-auc:0.741159
## [5] train-auc:0.748016
## [6] train-auc:0.752070
## [7] train-auc:0.754637
## [8] train-auc:0.759151
## [9] train-auc:0.762538
## [10] train-auc:0.769652
## [11] train-auc:0.776582
## [12] train-auc:0.780015
## [13] train-auc:0.782065
## [14] train-auc:0.782815
## [15] train-auc:0.788966
## [16] train-auc:0.791026
## [17] train-auc:0.793545
## [18] train-auc:0.797363
## [19] train-auc:0.799069
## [20] train-auc:0.802015
## [21] train-auc:0.802583
## [22] train-auc:0.806938
## [23] train-auc:0.808239
## [24] train-auc:0.811255
## [25] train-auc:0.813142
## [26] train-auc:0.816767
## [27] train-auc:0.817697
## [28] train-auc:0.820239
## [29] train-auc:0.821589
## [30] train-auc:0.823343
## [31] train-auc:0.823939
## [32] train-auc:0.825701
## [33] train-auc:0.827316
## [34] train-auc:0.829365
## [35] train-auc:0.832646
## [36] train-auc:0.833297
## [37] train-auc:0.837006
## [38] train-auc:0.838857
## [39] train-auc:0.839923
## [40] train-auc:0.842968
## [41] train-auc:0.844877
## [42] train-auc:0.845940
## [43] train-auc:0.846583
## [44] train-auc:0.847330
## [45] train-auc:0.848292
## [46] train-auc:0.850215
## [47] train-auc:0.851641
## [48] train-auc:0.852670
## [49] train-auc:0.854706
## [50] train-auc:0.855752
## [51] train-auc:0.856772
## [52] train-auc:0.857806
## [53] train-auc:0.860245
## [54] train-auc:0.861337
## [55] train-auc:0.864178
## [56] train-auc:0.865290
## [57] train-auc:0.865808
## [58] train-auc:0.866386
## [59] train-auc:0.867751
## [60] train-auc:0.870032
## [61] train-auc:0.870500
## [62] train-auc:0.872442
## [63] train-auc:0.873391
## [64] train-auc:0.875188
## [65] train-auc:0.877767
## [66] train-auc:0.879196
## [67] train-auc:0.880079
## [68] train-auc:0.879969
## [69] train-auc:0.880638
## [70] train-auc:0.881389
## [71] train-auc:0.882066
## [72] train-auc:0.882515
## [73] train-auc:0.883854
## [74] train-auc:0.884654
## [75] train-auc:0.885104
## [76] train-auc:0.885922
## [77] train-auc:0.887100
## [78] train-auc:0.888646
## [79] train-auc:0.889833
## [80] train-auc:0.890387
## [81] train-auc:0.891815
## [82] train-auc:0.892281
## [83] train-auc:0.894417
## [84] train-auc:0.895006
## [85] train-auc:0.897079
## [86] train-auc:0.899254
## [87] train-auc:0.901114
## [88] train-auc:0.902460
## [89] train-auc:0.902939
## [90] train-auc:0.903763
## [91] train-auc:0.903792
## [92] train-auc:0.904433
## [93] train-auc:0.904986
## [94] train-auc:0.907339
## [95] train-auc:0.907761
# Note: Plot AUC on for the in-sample train / validation scores – this was a note for me at the time of writing this R file – I never did get around to plotting the AUC for the in-sample train / validation scores…
What is nice about tree based models is that we can obtain importance scores from the model and find which variables contributed most to the gain in the model. The original paper explains more about the gain in Algorithm 1 and Algorithm 3 here.
# We can obtain “feature” importance results from the model.
xgb.imp <- xgb.importance(model = xgb.model)
xgb.plot.importance(xgb.imp, top_n = 10)
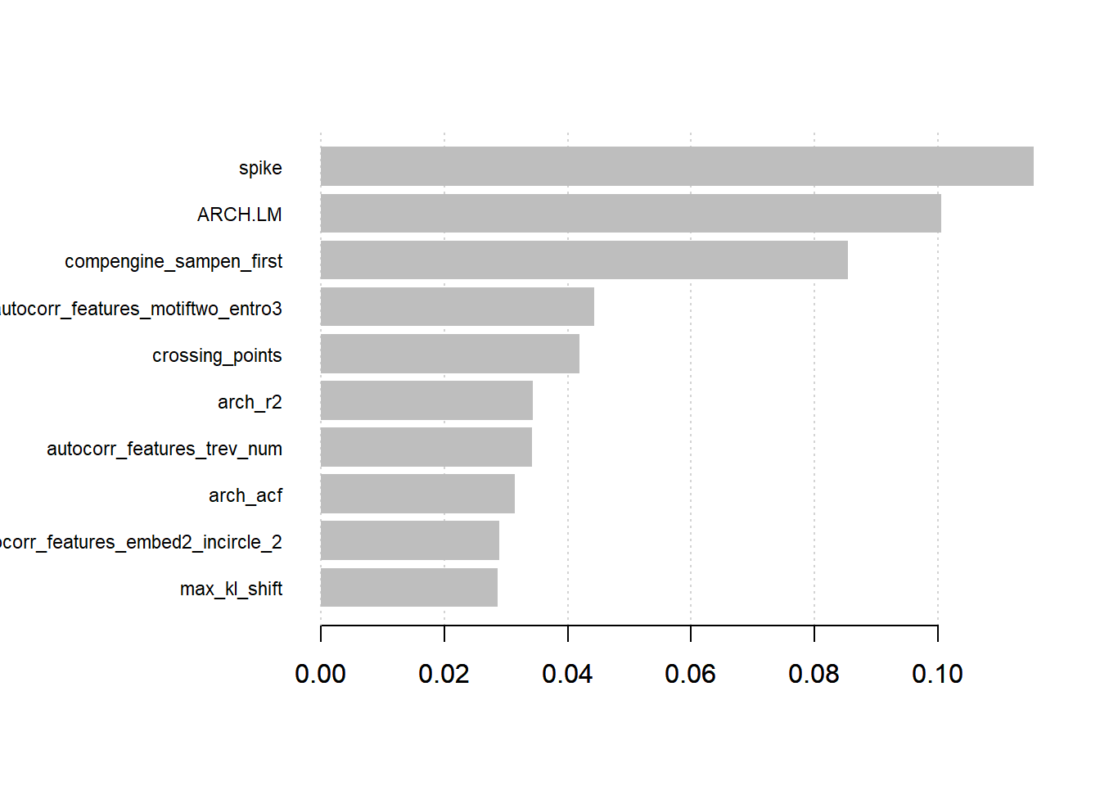
That is, the XGBoost model found that the spike was the most important variable. The spike comes from the stl_features function of the tsfeatures package in R. It computes various measures of trend and seasonality based on Seasonal and Trend Decomposition (STL) and measures the spikiness of a time series based on the variance of the leave-one-out variances of component e_t.
The second variable is interesting also and comes from the compengine feature set from the CompEngine database. It groups variables as autocorrelation, prediction, stationarity, distribution and scaling.
The ARCH.LM comes from the arch_stat function of the tsfeatures package and is based on the Lagrange Multiplier for Autoregressive Conditional Heteroscedasticity (ARCH) Engle 1982.
These are just a few of the variables the XGBoost model found to be the most important. A full overview and more information of the variables used in the model can be found here.
Visit Matthew Smith – R Blog to download the complete R code and see additional details featured in this tutorial: https://lf0.com/post/synth-real-time-series/financial-time-series/
Disclosure: Interactive Brokers
Information posted on IBKR Campus that is provided by third-parties does NOT constitute a recommendation that you should contract for the services of that third party. Third-party participants who contribute to IBKR Campus are independent of Interactive Brokers and Interactive Brokers does not make any representations or warranties concerning the services offered, their past or future performance, or the accuracy of the information provided by the third party. Past performance is no guarantee of future results.
This material is from Matthew Smith - R Blog and is being posted with its permission. The views expressed in this material are solely those of the author and/or Matthew Smith - R Blog and Interactive Brokers is not endorsing or recommending any investment or trading discussed in the material. This material is not and should not be construed as an offer to buy or sell any security. It should not be construed as research or investment advice or a recommendation to buy, sell or hold any security or commodity. This material does not and is not intended to take into account the particular financial conditions, investment objectives or requirements of individual customers. Before acting on this material, you should consider whether it is suitable for your particular circumstances and, as necessary, seek professional advice.